Introduction
monolish is a linear equation solver library that monolithically fuses variable data type, matrix structures, matrix data format, vendor specific data transfer APIs, and vendor specific numerical algebra libraries.
monolish is a vendor-independent open-source library written in C++ that aims to be a grand unified linear algebra library on any hardware.
BLAS has 150+ functions and LAPACK has 1000+ functions. These are complete software for dense matrix operations. However, these are not enough due to the growing needs of users. In particular, sparse matrix operations and machine learning kernels are not implemented.
To solve this, the libraries (MKL, cusolver, etc.) by each hardware vendor extended functions. Sadly, these software APIs are not unified. Moreover, These are language or vendor specific.
The BLAS library, including MKL and CUDA libraries, is the perfect library in terms of performance, but the function names depend on the data type. Python numpy, Julia, Matlab, etc. define APIs that eliminate these dependencies and call BLAS in them. Fast Sparse BLAS is implemented in MKL and CUDA Libraries. Sadly, there is no open-source Sparse BLAS library that works on all hardware. However, due to the needs of application users, the Python and Julia libraries have implemented Sparse BLAS on their own. The performance of these functions is not clear.
We think it is necessary to develop C/C++/Fortran libraries for dense and sparse matrices, which are the base of numerical computation. monolish is a monolithic C++ numerical library designed to bridge the gap between HPC engineers and application engineers.
monolish provides an API that integrates the numerical algebra libraries of each vendor. monolish calls the vendor-developed numerical algebra libraries whenever possible. monolish implements and provides functions that are not implemented in these libraries.
We dream that monolish will be used as a backend for python, Julia, etc. libraries in the future.
monolish solves cumbersome package management by Docker.
monolish uses OpenMP Offloading for GPU acceleration. Currently, only NVIDIA GPUs are supported. By using OpenMP Offloading, it is possible to support AMD Radeon and Intel Xe in the future.
Switching libraries
The first goal of monolish is to implement the basic operations that allow the BLAS, Sparse BLAS, and VML functions of the MKL and CUDA libraries to work on any hardware environment.
On Intel CPUs and NVIDIA GPUs, MKL and CUDA libraries are the fastest. The monolish uses these libraries as much as possible and implements the missing functions by itself.
When compiling, monolish switches the function to be called if the MKL or CUDA libraries are available or not. monolish wwitch dependency libraries at compile time.
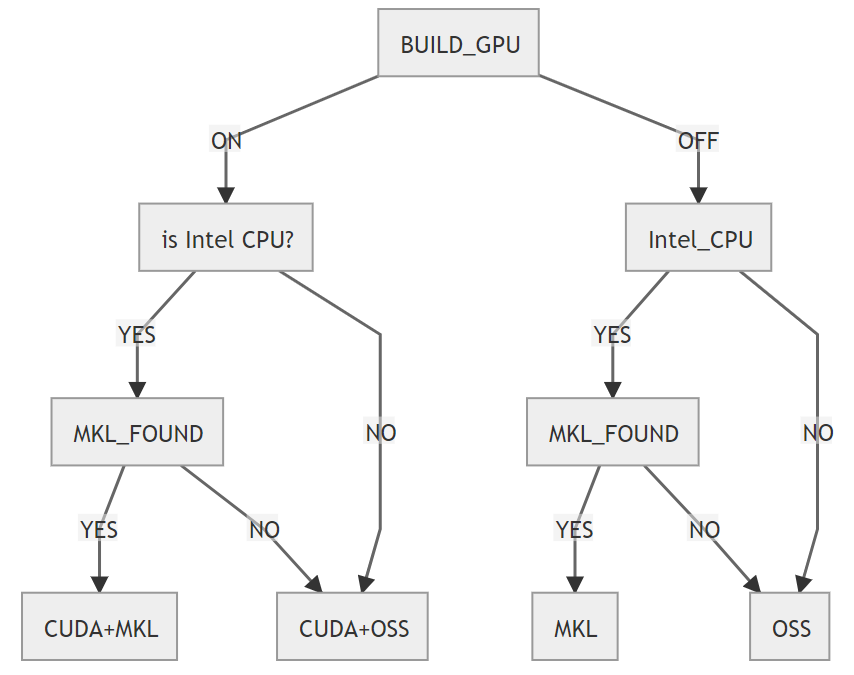
The current monolish has four branches, MKL, OSS, MKL + NVIDIA, and OSS + NVIDIA, as shown in the following figure.
The branch for the case where MKL or CUDA libraries are not available is called OSS. OSS is an implementation for architectures such as AMD, ARM, Power, etc. For example, in the case of Intel, monolish uses MKL, and in the case of OSS it uses OpenBLAS.
In OSS, we assume that only CBLAS compatible BLAS libraries and LAPACK can be used.
The functions of MKL and CUDA libraries that are not implemented in CBLAS are implemented in monolish. We plan to increase the number of libraries switching branches for AMD, ARM, and others.
Development policy for high performance
monolish has five development policies.
1. Don't require users to change programs due to changes in data types
Override functions and do not implement datatype-dependent functions.
In the future, imaginary numbers and high precision data types will be supported.
2. Don't require users to change their programs due to changes in hardware architecture.
monolish integrates vendor-implemented BLAS libraries and device communication APIs for each architecture. It provides a new layer to BLAS/LAPACK/Sparse BLAS that monolithically integrates types, matrix formats, and vendor-specific APIs.
To support AMD GPUs and Intel Xe with our own implementation, the internal device programs are implemented using OpenMP Offloading.
3. Don't require users to change their programs due to changes in the matrix storage format.
In monolish, all matrix formats, including Dense matrix, are defined as sparse matrix format.
The same interface is designed for all classes to minimize changes in user program due to the matrix storage format changes.
4. Don't implement functions that do not provide performance.
It is important to have the same functionality in all classes. However, there are operations that cannot be made faster in principle. For example, operations on columns of a matrix in CRS format.
If a useful function is implemented, many users will use it even if its performance is low. In monolish, even if there is a bias in functionality between classes, functions that are not fast enough in principle are not implemented.
We guarantee, as much as possible, that programs implemented with a combination of monolish functions will run fast.
If a function is absolutely necessary, warn the user by writing the number of computation in the documentation.
5. Don't allocate memory in ways that users cannot anticipate.
Compound functions and operator overloading are useful. However, they often require to allocate memory in the function for the return vector or matrix internally. users cannot anticipate this allocation.
In monolish, we do not implement functions that allocate memory in a way that is not intuitively expected by the user.
